一、概述
本文基于MYSQL 8.0,以新增特性:Invisible Indexes(隐藏索引)为基础,衍生讲述了数据库优化中各种索引的使用方式,以及常见的sql优化手段,以及常见索引在数据库底层的执行逻辑,本文如无特殊指定则默认引擎为InnoDB。
本文使用DMS(数据库管理软件):Navicat16.0.11、Aliyun DMS
二、EXPLAIN SQL执行计划分析
EXPLAIN关键字是市面上大部分数据库系统提供的一个分析SQL性能指标的关键性工具之一,EXPLAIN命令用于分析 SQL 查询的执行计划,帮助开发者理解查询的执行过程、优化性能(如索引使用、连接顺序等)。
其中MYSQL中对应字段的描述如下:
type字段对应内容说明:
Extra字段对应内容说明:
使用方式
EXPLAIN [ANALYZE] [FORMAT = JSON|TREE] SELECT * FROM [TABLE_NAME] WHERE XXX;效果演示
表sms_template:
CREATE TABLE `sms_template` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`template_code` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '短信模板编号',
`template_name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '短信模板名称',
`template_content` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '模板内容',
`sign_name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '短信签名',
`template_config_list` json DEFAULT NULL COMMENT '模板配置,json',
`retry` int NOT NULL DEFAULT '0' COMMENT '重试次数',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_template_code` (`template_code`),
UNIQUE KEY `uk_template_name` (`template_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC COMMENT='短信模板表';如图3.1所示,使用唯一索引字段template_code进行了等值查询,最终执行EXPLAIN指令后最终得出type为const,possible_keys、key(最终)中标识使用索引为uk_template_code,key_len为130表示仅用到了template_code 一列作为查询索引,根据key_len的计算方式得出 VARCHAR(32) = 4* 32 + 2 = 130

如图3.2所示,唯一索引字段template_name 使用前缀匹配,此时的type为range Extra字段为using index 标识当前查询使用索引uk_template_name进行范围查找

如图3.3所示,使用非索引字段sign_name进行查询以及分组,则type为ALL Extra字段内容为Using where、 Using temporary 其中Filtered为11.11表示,查询再存储引擎中查询除了rows=19条记录,而优化器预估只有2条符合条件则当前查询的命中率低。

三、各索引类型及使用技巧
主键索引:数据列不允许重复,不允许为NULL,一个表只能有一个主键,也为“聚集索引”。
普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和NULL值。
实现原理
普通索引在MySQL中采用HASH或者B(+)树作为存储结构,普通索引没有限制,但是需要遵循“索引的选择性原则”。
索引的选择性是指索引列中不同值的数量与表中记录总数的比例。高选择性的列(如用户ID、手机号)更适合创建索引,而低选择性的列(如性别、状态标志)则索引效果有限。
-- 计算列的选择性 SELECT COUNT(DISTINCT column_name) / COUNT(*) AS selectivity FROM table_name;使用方式
CREATE INDEX [index_name] ON [table_name] (column1 [ASC|DESC], column2 [ASC|DESC], ...);唯一索引:索引列中的值必须是唯一的,但是允许NULL值。
实现原理
MySQL中唯一索引如没有特殊指定则采用B(+)树作为底层数据结构,当标注了唯一索引的字段有新增/修改数据时,将数据再B(+)树中比较是否有重复值,唯一索引允许一个或者多个NULL值。
使用方式
-- 唯一索引 ALTER TABLE [table_name] ADD UNIQUE INDEX [index_name] (column1 [ASC|DESC],column2 ) USING BTREE;前缀索引:在文本类型如BLOB、TEXT或者很长的VARCHAR列上创建索引时,可以使用前缀索引,数据量相比普通索引更小,可以指定索引列的长度,但是数值类型不能指定。
实现原理
前缀索引本质上是指定了内容长度的普通索引,具体实现逻辑为,通过“不重复的索引值与数据总量的比值(图2.1)”的SQL计算出不重复率最高的前缀长度,并通过创建普通索引的形式截取指定长度的内容创建索引,判断长度需要基于具体业务来决策。
该索引比较适合字符长度较为固定的数据类型,例如邮箱、手机号前缀...等。
对于使用行格式的
InnoDB表, 前缀最长可达 767 个字节 。 对于使用or 行格式的表, 前缀长度限制为 3072 字节 。对于MyISAM表,前缀长度限制为 1000 字节(原文)。使用方式
-- 获取 不重复的索引值与数据总量的比值 SELECT COUNT(DISTINCT LEFT(字段1,字符长度3))/COUNT(1) AS selectivity3, COUNT(DISTINCT LEFT(字段1,字符长度4))/COUNT(1) AS selectivity4, COUNT(DISTINCT LEFT(字段1,字符长度5))/COUNT(1) AS selectivity5, COUNT(DISTINCT LEFT(字段1,字符长度6))/COUNT(1) AS selectivity6, COUNT(DISTINCT LEFT(字段1,字符长度7))/COUNT(1) AS selectivity7, COUNT(DISTINCT LEFT(字段1,字符长度8))/COUNT(1) AS selectivity8, COUNT(DISTINCT LEFT(字段1,字符长度9))/COUNT(1) AS selectivity9 ... FROM 源数据表名; -- 创建前缀索引 ALTER TABLE [table_name] ADD INDEX [index_name](column(count));效果展示
如图2.1所示,通过计算比值算出,字符长度9的不重复率高达60%

如图2.2 实际上使用会发现针对手机号创建了8位的前缀索引,但是实际上走的是“uk_mobile”这个索引,所以针对mobile实际上不需要创建前缀索引。

如图2.3 所示 计算了user_info字段中的真实姓名字段其中前6位已经满足不重复率的要求(仅作为演示索引创建流程)。
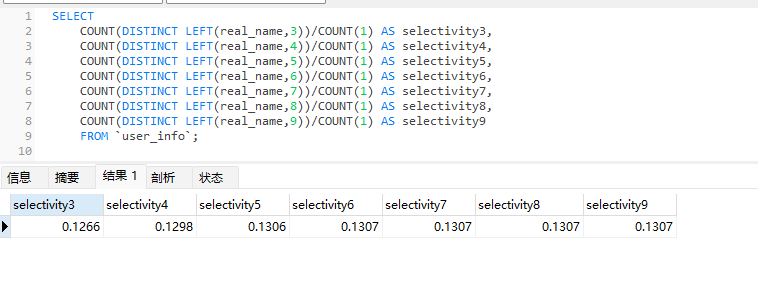
如图2.4 创建了姓名前5位(按需求指定)的前缀索引,并使用Explan分析sql最终走到了“idx_real_name_prefix”索引中。

弊端
维护索引需要消耗资源,过长的前缀索引在效率上不一定比普通索引更优,对于长度变化比较大的字段,例如文章内容等大文本字段维护会消耗更多的资源,并且索引覆盖率不高,通常索引的不重复率高于80%比较适合建立索引,否则不提倡(上图仅为演示创建流程)。
组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。
空间索引:MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型。该索引要求字段类型必须是
GEOMETRY,POINT,LINESTRING,POLYGON等空间数据类型实现原理
空间索引中的“空间”的概念主要为将二维及以上的数据转化为一维数据格式展示,例如经纬度、球形弧度等等,核心数据结构最经典为“R树”,R树是B树的高维扩展,旨在将高纬度的数据划分为若干个小的数据单元格,数据入库会进入到符合范围的单元格中,每个单元格内会再次划分子单元格,最终写入到由B(+)树构成的最终单元格数据集合中。
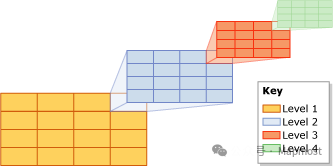
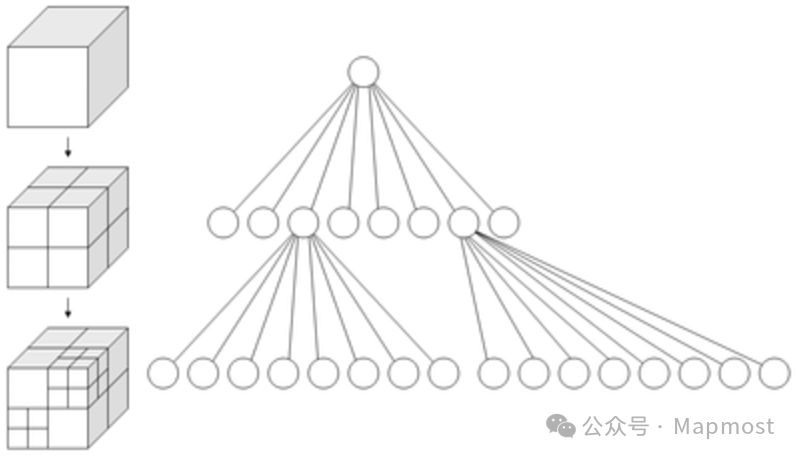
在MySQL中使用“SPATIAL”关键词创建空间索引,不过需要注意的是,该索引目前仅支持“GEOMETRY(保存所有类型)”、“POINT”等几何类型的数据类型(原文)
使用方式
-- 创建索引 ALTER TABLE [table_name] ADD SPATIAL INDEX(column); -- 具体使用方式可以查看 https://www.mysqlzh.com/doc/176/147.html -- 查询空间索引列需要搭配对应的空间函数倒排索引(概念扩展同全文索引):针对搜索引擎或者需要大量检索文档场景下诞生的索引类型,再MYSQL中为全文索引(FULLTEXT),旨在针对大批量文本搜索优化。
实现原理:
倒排索引中的”倒排“这一概念指的是,由常规的“索引-》内容“转换为”内容-》索引“,其核心思想是将文本内容按照特定粒度划分后,构建出由文本组成的字符树,而字符树的叶子节点为”索引“。
以下代码为倒排索引的JAVADEMO简单实现旨在帮助学习,MySQL内部的
FULLTEXT索引实现要复杂得多,其中文本内容采用jieba工具进行分词,并使用Map对索引进行保存。
import com.huaban.analysis.jieba.JiebaSegmenter; import java.util.ArrayList; import java.util.HashSet; import java.util.List; import java.util.Set; import java.util.concurrent.*; /** * 倒排索引的简单实现 */ public class InvertIndex { /** * 待索引内容 */ private static final List<String> contentList = List.of( "I am a student. I am from China. I study in Xi'an Jiaotong University.", "I hello nihao 你好啊", "am you "); /** * 初始化索引 */ private static final ConcurrentHashMap<String, ConcurrentSkipListSet<Integer>> invertIndex = new ConcurrentHashMap<>(); /** * 初始化分词 */ private static final JiebaSegmenter segmenter = new JiebaSegmenter(); public static void main(String[] args) throws InterruptedException { //倒排索引实现 initContentList(); System.out.println(invertIndex); System.out.println(find("am I")); } /** * 初始化倒排索引 */ public static void initContentList() throws InterruptedException { ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor(); CountDownLatch latch = new CountDownLatch(contentList.size()); for (int i = 0; i < contentList.size(); i++) { final String str = contentList.get(i); int finalI = i; executorService.execute(() -> { List<String> words = segmenter.sentenceProcess(str); for (String word : words) { if (word.trim().isEmpty()){ continue; } if (!invertIndex.containsKey(word)) { invertIndex.put(word, new ConcurrentSkipListSet<>()); } invertIndex.get(word).add(finalI); latch.countDown(); } }); } latch.await(); } /** * 查询索引根据指定内容返回索引,并且将关联度最高返回 * @param text * @return */ public static List<Integer> find(String text){ List<String> words = segmenter.sentenceProcess(text); if (words.isEmpty()) { return List.of(); } // 查找所有索引,并且把包含所有关键词的文档优先展示 Set<Integer> intersectionSet = null; // 关键词交集 Set<Integer> unionSet = new HashSet<>(); // 关键词并集 for (String word : words) { ConcurrentSkipListSet<Integer> indexes = invertIndex.get(word); if (indexes == null || indexes.isEmpty()) { // 如果某个关键词不存在,则只返回并集结果 continue; } if (intersectionSet == null) { // 第一次直接赋值 intersectionSet = new HashSet<>(indexes); } else { // 后续求交集 intersectionSet.retainAll(indexes); } // 添加到并集 unionSet.addAll(indexes); } // 处理结果:先返回交集,再返回差集(只在并集中但不在交集中的元素) List<Integer> result = new ArrayList<>(); // 如果有交集,添加交集结果 if (intersectionSet != null) { result.addAll(intersectionSet); // 添加差集(在并集中但不在交集中的元素) unionSet.removeAll(intersectionSet); } // 添加剩余的并集元素 result.addAll(unionSet); return result; } }使用方式
-- 创建全文索引 ALTER TABLE [table_name] ADD FULLTEXT INDEX [index_name] (column1, column2...) WITH PARSER ngram; -- 可选中文分词器 -- 使用自然语言模式进行全文搜索 SELECT * FROM [table_name] WHERE MATCH(column1, column2) AGAINST('检索内容1','检索内容2');
四、高级技巧以及实践
索引管理工具
SHOW INDEX / SHOW KEYS
SHOW INDEX FROM `your_table_name`;
-- 或
SHOW KEYS FROM `your_table_name`;如图4.1所示,执行show index/show keys 后得出sms_template中创建索引信息其中Cardinality对于索引优化至关重要,代表着当前索引的数据大小,必要时需要通过ANALYZE TABLE更新。

sys.schema视图(MySQL 5.7+)
该视图属于系统视图需要有对应权限才可执行,视图中提供了由MYSQL为我们分析冗余索引、未使用索引、以及索引执行次数等信息,基于这类信息可以自行决定索引是否需要保留。
-- 查找冗余索引
SELECT * FROM sys.schema_redundant_indexes;
-- 查找从未使用过的索引
SELECT * FROM sys.schema_unused_indexes;
-- 查看索引统计信息,如查询次数等
SELECT * FROM sys.schema_index_statistics;Percona ToolkitPercona Toolkit是 MySQL DBA 的瑞士军刀,一组高级命令行工具的集合,用来执行各种通过手工执行非常复杂和麻烦的MySQL和系统任务,本文仅介绍与索引相关的常用命令。PS:Percona Toolkit是第三方工具,需要安装后使用。pt-duplicate-key-checker自动扫描数据库,并生成报告指出哪些索引是重复或可以被合并的。
pt-duplicate-key-checker --user=username --password=password --database=your_databasept-index-usage
分析慢查询日志,找出哪些索引从未被使用过。比
sys.schema_unused_indexes更强大,因为它基于真实的查询负载。分析结果基于实际流量,非常可靠。pt-index-usage /path/to/slow.log --host localhost --user username --password password
隐藏索引
删除、创建索引时推荐使用MYSQL8.x新增特性Invisible Indexes(隐藏索引),隐藏索引这一特性,使得在生产环境中因为误操作索引导致的破坏性极大地减小,它能够在不进行破坏性更改的情况下测试删除,修改索引所产生的影响,并且能适时回滚。
使用方式:
-- 创建隐藏索引
CREATE INDEX [index_name] ON [table_name] ([column...]) [INVISIBLE/VISIBLE];
ALTER TABLE [table_name] ADD INDEX [index_name] ([column...]) [INVISIBLE/VISIBLE];
-- 修改现有索引的可见性
ALTER TABLE [table_name] ALTER INDEX [index_name] [INVISIBLE/VISIBLE];通过INVISIBLE/VISIBLE指定是否显示应用索引,并通过EXPLAIN(MYSQL中用于分析该sql的执行效果)
EXPLAIN SELECT /*+ SET_VAR(optimizer_switch = 'use_invisible_indexes=on') */
column... from [table_name] WHERE column = 64;效果演示:
如图3.1所示,创建了隐藏索引设置为INVISIBLE 常规语句并不会使用

如图3.2所示,通过设置当前会话的optimizer_switch变量为use_invisible_indexes=on 可以指定当前SQL是否使用隐藏索引

如图3.3所示当索引设置为VISIBLE时,常规SQL语句也会正常使用该索引

弊端:
隐藏索引与普通索引一致,存放在物理磁盘空间,数据库进行写操作时同步也会维护隐藏索引,如果创建过多的隐藏索引会导致物理磁盘空间的占用,以及增加索引维护的写开销。
注意点:
该特性仅支持MYSQL8.X+,主键索引不支持设置为不可见,唯一索引即使设置为不可见仍然会约束数据的唯一性,且表中如不存在主键索引且唯一索引指定的列如果设置为NOT NULL 也不可设置为INVISIBLE;
通过以下语句可以查看当前表中是否有隐藏索引
SELECT index_name, is_visible
FROM INFORMATION_SCHEMA.STATISTICS
WHERE table_name = '[table_name]';常见场景优化案例
场景1
我们有一个用户行为日志表 user_actions,主要用于分析用户活跃情况:
CREATE TABLE user_actions (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
action_type VARCHAR(20) NOT NULL, -- 'login', 'purchase', 'view'等
action_time DATETIME NOT NULL,
device VARCHAR(50),
ip_address VARCHAR(15),
extra_info JSON
) ENGINE=InnoDB;
-- 现有索引
INDEX idx_user_id (user_id),
INDEX idx_action_time (action_time);
-- 需要优化SQL
SELECT user_id, action_type, action_time
FROM user_actions
WHERE action_type = 'purchase'
AND action_time >= '2024-01-01'
AND action_time < '2024-02-01'
ORDER BY action_time DESC
LIMIT 1000;当前查询的性能瓶颈是什么?
如何优化这个查询?请说明具体的优化方案和原理。
如果业务需要频繁按不同
action_type和时间范围查询,应该如何设计索引?
答:
瓶颈在于没有合适的复合索引,导致可能全表扫描或使用低效的索引。
优化方案是创建
(action_type, action_time)复合索引,这样可以利用索引完成过滤和排序。对于频繁的多维度查询,可以考虑创建多个复合索引,如
(action_type, action_time)、(user_id, action_time)等,但要注意索引维护成本。
-- 创建复合索引,将等值查询条件放在前面,范围查询和排序字段放在后面
ALTER TABLE user_actions ADD INDEX idx_type_time (action_type, action_time);
-- 优化后的查询保持不变,但执行计划会使用新索引
SELECT user_id, action_type, action_time
FROM user_actions
WHERE action_type = 'purchase'
AND action_time >= '2024-01-01'
AND action_time < '2024-02-01'
ORDER BY action_time DESC
LIMIT 1000;场景2
电商订单表,数据量约5000万条:
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
order_amount DECIMAL(10,2) NOT NULL,
status TINYINT NOT NULL, -- 1:待支付 2:已支付 3:已发货 4:已完成
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL,
INDEX idx_user_id (user_id),
INDEX idx_create_time (create_time)
) ENGINE=InnoDB;
-- 问题SQL
-- 用户查看第100页的订单列表(每页20条)
SELECT order_id, user_id, order_amount, status, create_time
FROM orders
WHERE user_id = 12345
AND status IN (2, 3, 4)
ORDER BY create_time DESC
LIMIT 1980, 20; -- (100-1)*20 = 1980为什么这个分页查询在深度分页时性能很差?
请提供至少两种优化方案,并比较它们的优缺点。
如果
user_id=12345的订单有10万条,你的优化方案能提升多少性能?
答:
深度分页慢是因为OFFSET需要遍历并丢弃前N条记录。
游标分页通过记录上一页最后一条的位置来直接定位,性能最好但不支持随机跳页;延迟关联通过子查询先获取ID再关联,比直接OFFSET快很多。
对于10万条数据,游标分页可以将查询时间从秒级降到毫秒级。
-- 第一页
SELECT order_id, user_id, order_amount, status, create_time
FROM orders
WHERE user_id = 12345
AND status IN (2, 3, 4)
ORDER BY create_time DESC
LIMIT 20;
-- 下一页(假设上一页最后一条 order_id为 5000)
SELECT order_id, user_id, order_amount, status, create_time
FROM orders
WHERE user_id = 12345
AND status IN (2, 3, 4)
AND order_id > 5000
ORDER BY create_time DESC
LIMIT 20;SELECT o.order_id, o.user_id, o.order_amount, o.status, o.create_time
FROM orders o
INNER JOIN (
SELECT order_id
FROM orders
WHERE user_id = 12345
AND status IN (2, 3, 4)
ORDER BY create_time DESC
LIMIT 1980, 20
) AS tmp ON o.order_id = tmp.order_id
ORDER BY o.create_time DESC;场景3
电商系统的三张核心表:
-- 用户表
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
reg_time DATETIME NOT NULL,
vip_level TINYINT DEFAULT 1,
INDEX idx_reg_time (reg_time)
);
-- 商品表
CREATE TABLE products (
product_id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(100) NOT NULL,
category_id INT NOT NULL,
price DECIMAL(10,2) NOT NULL,
status TINYINT DEFAULT 1,
INDEX idx_category (category_id)
);
-- 订单表(大表,约2亿条记录)
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL,
order_amount DECIMAL(10,2) NOT NULL,
order_time DATETIME NOT NULL,
INDEX idx_user_id (user_id),
INDEX idx_order_time (order_time)
) ENGINE=InnoDB;
-- 问题SQL
-- 统计2024年第一季度VIP用户(level>=3)的购买行为,按商品类别分组
SELECT
p.category_id,
COUNT(DISTINCT o.user_id) as buyer_count,
SUM(o.quantity) as total_quantity,
AVG(o.order_amount) as avg_amount
FROM orders o
JOIN users u ON o.user_id = u.user_id
JOIN products p ON o.product_id = p.product_id
WHERE u.vip_level >= 3
AND o.order_time >= '2024-01-01'
AND o.order_time < '2024-04-01'
AND p.status = 1
GROUP BY p.category_id
ORDER BY total_quantity DESC;分析这个查询可能存在的性能瓶颈点。
如何优化表结构和索引来提升这个查询的性能?
答:
瓶颈主要在大表扫描、错误的JOIN顺序、缺失的复合索引和大量的聚合操作。
需要为每个表的过滤条件和JOIN条件创建复合索引,考虑使用STRAIGHT_JOIN控制执行顺序。
-- orders表:为时间范围和JOIN条件创建复合索引
ALTER TABLE orders ADD INDEX idx_time_user_product (order_time, user_id, product_id);
-- users表:为VIP过滤创建索引
ALTER TABLE users ADD INDEX idx_vip_level (vip_level, user_id);
-- products表:为状态过滤创建索引
ALTER TABLE products ADD INDEX idx_status_category (status, category_id, product_id);STRAIGHT_JOIN 是 MySQL 中的一种特殊连接方式,它与普通的 JOIN 类似,但有一个重要区别:左表始终在右表之前读取。这种方式可以用于优化器在某些情况下按顺序处理表的情况。
注意:STRAIGHT_JOIN必须谨慎使用,因为它剥夺了MYSQL优化器的选择连接顺序的权利,只有在明确知道某个连接顺序(通常是从数据量最小或过滤性最好的表开始)远优于优化器选择时才使用。滥用可能导致性能下降。
-- 使用STRAIGHT_JOIN强制优化器使用正确的JOIN顺序
SELECT
p.category_id,
COUNT(DISTINCT o.user_id) as buyer_count,
SUM(o.quantity) as total_quantity,
AVG(o.order_amount) as avg_amount
FROM orders o
STRAIGHT_JOIN users u ON o.user_id = u.user_id
STRAIGHT_JOIN products p ON o.product_id = p.product_id
WHERE u.vip_level >= 3
AND o.order_time >= '2024-01-01'
AND o.order_time < '2024-04-01'
AND p.status = 1
GROUP BY p.category_id
ORDER BY total_quantity DESC;-- 分阶段处理,先过滤再JOIN
SELECT
p.category_id,
COUNT(DISTINCT tmp.user_id) as buyer_count,
SUM(tmp.quantity) as total_quantity,
AVG(tmp.order_amount) as avg_amount
FROM (
SELECT o.user_id, o.product_id, o.quantity, o.order_amount
FROM orders o
WHERE o.order_time >= '2024-01-01'
AND o.order_time < '2024-04-01'
) tmp
JOIN users u ON tmp.user_id = u.user_id AND u.vip_level >= 3
JOIN products p ON tmp.product_id = p.product_id AND p.status = 1
GROUP BY p.category_id
ORDER BY total_quantity DESC;五、总结
关键优化建议总结
核心思想
索引不是越多越好,要基于查询模式和数据分布合理设计。
理解EXPLAIN是优化SQL的基础。
复合索引顺序非常重要,应遵循“等值查询 → 范围查询 → 排序”原则。
MySQL 8.0+ 新特性(如隐藏索引、系统视图)能显著提升索引管理的安全性和效率。